【ビジネス統計スペシャリストに合格】スプレッドシートを活用しよう!

はじめに
この記事では下記の2点が分かります。
1:スプレッドシートでXLMiner Analysis ToolPakを有効にする方法
2:エクセル分析スペシャリストで使用する分析ツールの概要
ご訪問ありがとうございます!まちゅけんです。
ヨメちゃんです。
この記事ではエクセル分析スペシャリストで使用する分析ツールをGoogleのスプレッドシートで行う方法を解説します。Excelを使った操作は別の記事があるので下記の記事をお読み下さい。

そもそもとして
「ビジネス統計スペシャリストってなんだ?」
「もっと概要や勉強方法が知りたい!」
という方については下記の記事を参照して下さい。


XLMiner Analysis ToolPakの導入
スプレッドシートではアドインという拡張機能を使って、『XLMiner Analysis ToolPak』をインストールします。Microsoft社が提供する拡張機能ですので、操作性はExcelにとても類似しています。しかも無料で利用することができるので、Excelを導入していない方には打ってつけです。こちらの機能概要はMicrosoft社の公式サイトでご確認下さい。
それでは拡張機能の設定方法について解説します。
Googleアプリを開く
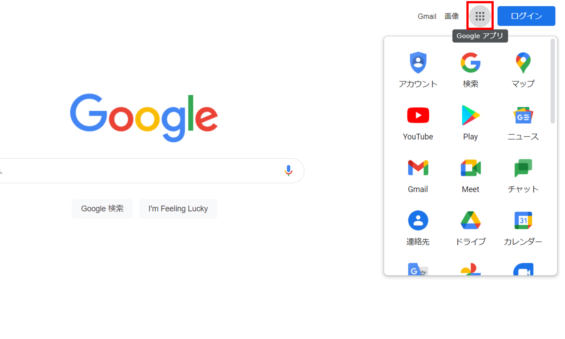
Googleのブラウザを立ち上げてGoogleアプリをクリックします。
スプレッドシートを開く

スプレッドシートを選択します。
新規シートを作成する
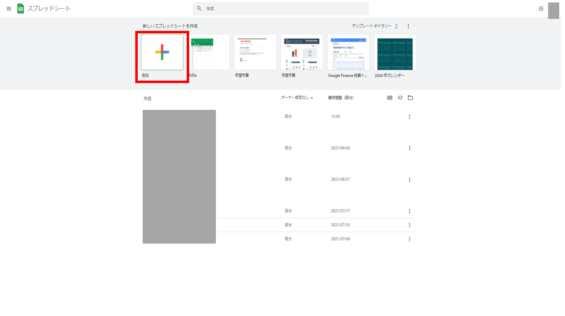
スプレッドシートが立ち上がるのでシートを新規作成します。
アドオンを開く
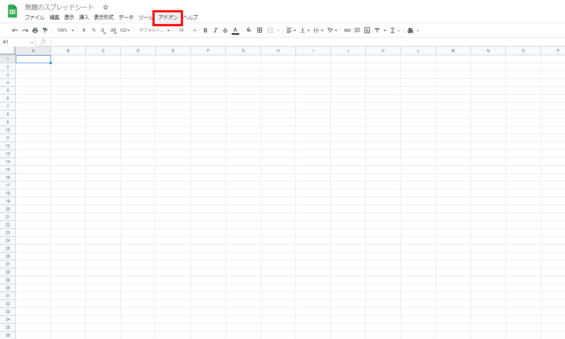
スプレッドシートの初期画面ですアドオンをクリックして下さい。
アドオンを取得する
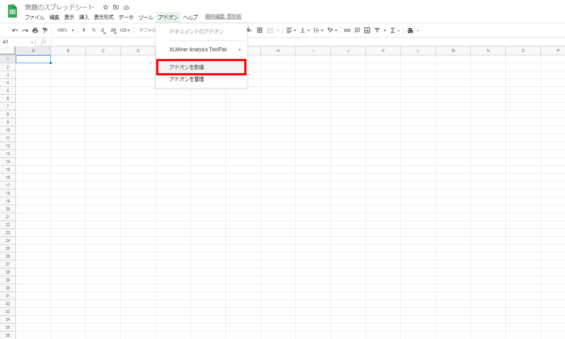
アドオンを取得します。あと少し!
XLMiner Analysis ToolPak を検索
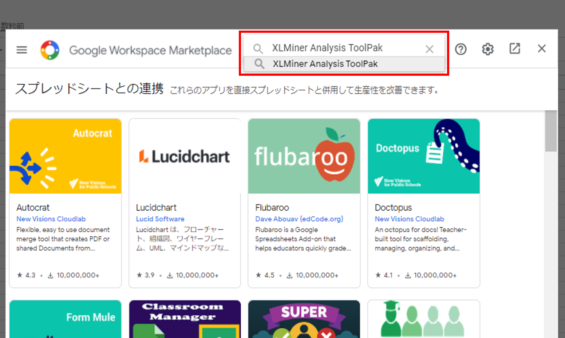
XLMiner Analysis ToolPakを検索します。
XLMiner Analysis ToolPak を選択
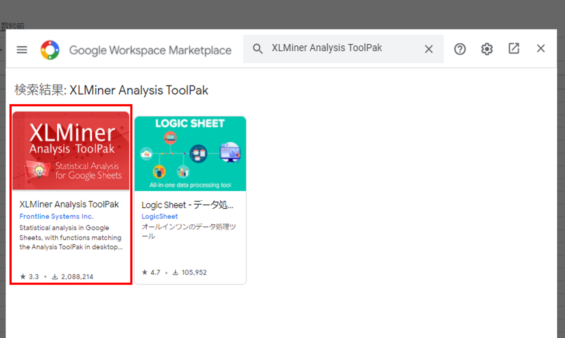
XLMiner Analysis ToolPakを選択します。
インストールする
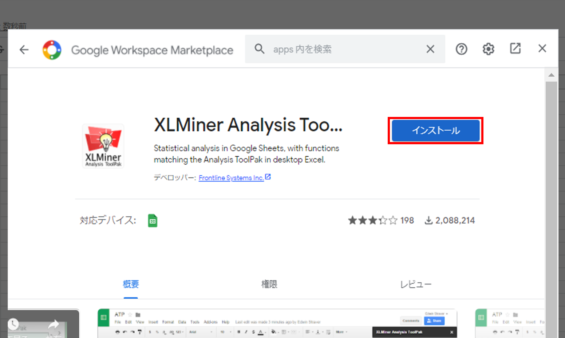
インストールをして下さい。
完了する
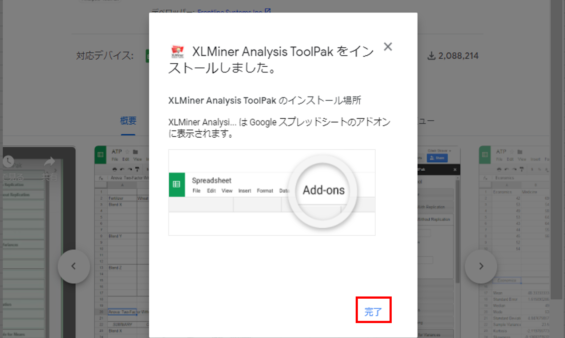
インストールが完了しました!完了を押して下さい。
アドオンを開く
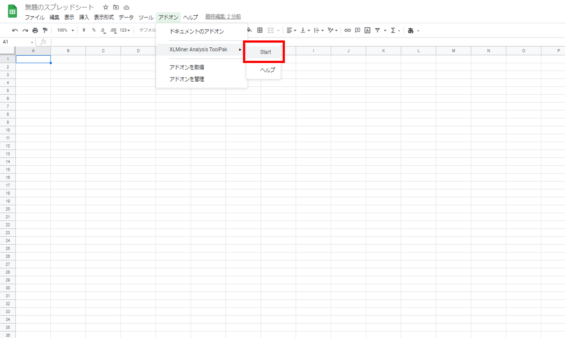
もう一度アドオンをクリックします。XLMiner Analysis ToolPakが有効になっているのでStartをクリックします。
XLMiner Analysis ToolPakの起動
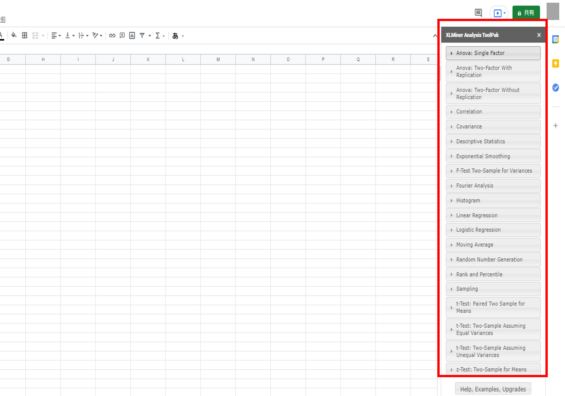
分析ツールが立ち上がりました!これで操作は以上です。
簡単でしょ?
簡単!だけど分析ツールの名前が全部英語なんだけど…。
そうなのです。Excelのデータ分析ツールは表記が日本語ですが、スプレッドシートでは全て英語になっています。安心して下さい。全て説明します。
分析ツールの説明
スプレッドシートで使用できる分析ツールは全部で19種類ありますがエクセル分析スペシャリストで使用するツールは限られています。なのでここでは実際の試験で使用するツールだけに絞ってそれぞれの用途を英語表記も含めて解説します。
●Anova: Single Factor(分散分析:一元配置)
●Correlation(相関)
●Covariance(共分散)
●Descriptive Statistics(基本統計量)
●F-Test Two-Sample for Variances(F検定:2標本を使った分散の分析)
●Histogram(ヒストグラム)
●Linear Regression(回帰分析)
●t-Test(t検定)
…t-Test: Paired Two Sample for Means(一対の標本による平均の検定)
…t-Test: Two-Sample Assuming Equal Variances(等分散を仮定した2標本による検定)
…t-Test: Two-Sample Assuming Unequal Variances(分散が等しくないと仮定した2標本による検定)
Anova: Single Factor
日本語では分散分析:一元配置です。
3つ以上の標本の平均値を比較して有意に差があるかどうかを調べるために使用するツールです。
・・・と言うだけでは説明がパッとしませんので例え話をします。
ある中学校の3年生は1・2・3組があるとします。それぞれ担任の先生はこんな会話をします。
1組担任「古文の成績がいいのはうちのクラスだね」
2組担任「平均点はうちが一番高いよ!」
3組担任「うちのクラスには学年トップの田中と山田がいるからな」
どの先生も自分のクラスが優秀だと疑いません。そんなときに活用できるのが一元配置分散分析です。通常は各クラスの平均点を比較することを真っ先に思い浮かびますが、もしかしたら3組の担任が言っているように、特定の生徒だけがズバ抜けて優秀かもしれません。もしくは2組の平均点が一番高いと言っても1点高いだけかもしれません。このように平均点を比較するだけでは公平性に欠けていたり、たまたま出た結果かもしれない可能性を捨てきることができません。その点一元配置分散分析では、それぞれの平均点の差が生じたのはたまたまだったのかを分析することができます。
具体的な操作方法はコチラ
【ビジネス統計スペシャリスト対策】スプレッドシートで一元配置分散分析をする方法
Correlation
日本語では相関です。
片方の数値が上がるとき、もう一方の数値も上がる(もしくは下がる)傾向にあるかなど、二つの変数の関係性を調べる時に使います。
「古文の点数が高いクラスは漢文の点数が高いのか」
「イケメンはバレンタインデーにチョコをたくさんもらうのか」
「気温が高い日はアイスが多く売れるのか」
など、二つの変数の関係性の強さを数値(相関係数)として表すことができます。
Covariance
日本語では共分散です。
共分散も二つの変数の関係性を調べることに変わりはありません。
「あるクラスの古文の平均点と勉強時間の関係性を調べたい」といった時は共分散を使用します。
共分散が正の値を取る時、勉強時間が増えるほど古文の点数は増えます。逆に共分散が負の値を取る時は、勉強をするほど古文の点数が下がることになってしまいます。
「え、じゃあ相関係数っていらなくない?」と思うかもしれませんが実はそうでもありません。
共分散では古文の平均点と勉強時間の関係性を表すことができると言いました。では古文&勉強時間と漢文&勉強時間ではどちらの関係性が強いのかを考えます。残念ながら共分散を比較するだけでは関係性の強さを比較することができません。共分散は古文&勉強時間のようにワンペアでの関係性の強さを知ることしかできないため、全く指標のことなる古文と漢文を比較できないのです。ここで活用できるのが相関係数です。相関係数では古文と漢文の指標の違いも加味した計算式を使うため、関係性の違いを比較することができます。
Descriptive Statistics
日本語では基本統計量です。
データの基本的な特性を算出することができます。例えるならデータのプロフィールです。
47都道府県ごとに全てのドラッグストアの1日の売上を比較するとします。
「一番売り上げの高い店舗は何県にある?」
「売上の開きが一番大きいのは何県?」
「店舗数が一番少ないのは何県?」
「県内で一番売り上げのバラつきがあるのは何県?」
みたいな疑問は全て基本統計量が解決してくれます。
・平均
・標準誤差
・中央値
・最頻値
・標準偏差
・分散
・尖度
・歪度
・範囲
・最小
・最大
・合計
・データの個数
F-Test Two-Sample for Variances
日本語ではF検定:2標本を使った分散の分析です。
二つの標本の分散が等しいかを調べる分析です。大体はt検定の前に使用します。
「経理部と総務部の給料ではどちらにバラつきがあるだろうか」みたいなことを考えたいときにはF検定が便利です。仮に経理部と総務部では平均給料が同じでも、経理部では極端に多いひとや少ないひとがいるかもしれません。F検定ではそういった部毎に給料のバラつきが等しいかを知ることができます。
Histogram
日本語ではヒストグラムです。
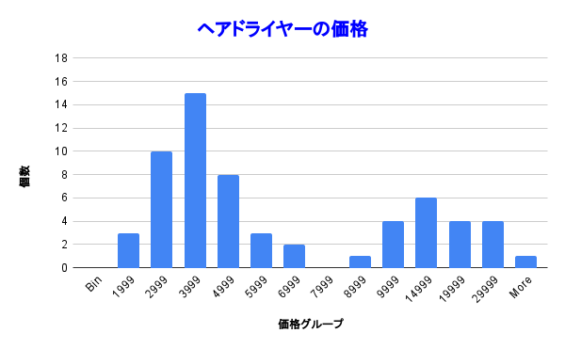
こんな感じのグラフを見たことがありますでしょうか。これがヒストグラムです。あるデータの集まりを区間ごとに区切ってカウントしたものを見える化したものを指します。
Linear Regression
日本語では回帰分析です。
結果の数値と、その数値を生み出した原因の関係を導き出すためのツールです。
「晴れと曇りではお店の売上がいくら変わるか?」
「看板とメールではどちらが集客になるか?」
「遊園地が一番混むのは何曜日か?」
といった関係性を数式化して求めることができるのが回帰分析です。
t-Test
日本語ではt検定です。
二つの標本データの平均を比較するのがt検定です。
「ニつの平均値が異なっていることに意味があるか?偶然か?」
みたなことを知ることが出来ます。また用意する標本によって使用するツールは異なります。具体例も交えると以下の通りです。
●t-Test: Paired Two Sample for Means
日本語では一対の標本による平均の検定です。
一対の標本というのは比較をするデータの発生源が同じものを指します。対応のあるデータと言ったりもします。ある大学の講義前と後のテストの成績を比較したり、運動前と運動後の体重変化などが該当します。
●t-Test: Two-Sample Assuming Equal Variances
日本語では等分散を仮定した2標本による検定です
一対の標本ではない場合の平均の検定を指します。男女の身長差、日本と中国の所得差、クラスAとクラスBのテストの点数の差などがあたります。ポイントは、ニつの標本の分散が等しいと仮定をして計算をすることです。t検定の前にF検定を通じて等分散の有無を調べます。このt検定は別名スチューデントのt検定と呼ばれています。
●t-Test: Two-Sample Assuming Unequal Variances
日本語では分散が等しくないと仮定した2標本による検定です。
このt検定ではニつの標本の分散が等しくないと仮定をして検定を行います。一般的には等分散を仮定しないツールを使うことの方が多いようです。ウェルチのt検定とも言います。
まとめ
今回はスプレッドシートでデータ分析ツールを使用する方法と、実際の試験でも使用する分析ツールについて紹介しました。それぞれの分析ツールを使った具体的な操作方法についてもこれからの記事の中で解説しますので楽しみにしていて下さい。
もしビジネス統計スペシャリストに興味が沸いた方は以前書いた記事を参考にして下さい。
統計学はデータサイエンティストなど一部の職業に限った知識ではなく、私たちの普段の仕事にも大いに役立つ学問です。この記事をきっかけに興味を持っていただければ嬉しい限りです。
お読みいただきありがとうございました!
ありがとうございました!